
在linux系统优化中,我们经常看到cache/buffer,但是什么是cache,什么是buffer呢,他们之间有没有区别?
从字面意思来看,cache是缓存,buffer是缓冲。这里假设有两个设备,分别叫A和B,由于制作工艺的差别,A的处理速度远远大于B。假设A和B在接口速度上有一定的差别,A接口速度为10M/s,B接口速度为5M/s.现在B中有件事需要A处理,命名为B1, 大小为10M,如下图所示:
A<————->B(B1)
那么在处理这个事件会出现这种情况,1.A拿到B1需要2s,因为B的接口只为5M/s;2.同样A处理完还给B也需要2s。在这个过程中A一半的时间都在等待传输上。
若何优化这个过程呢,我们可以在A和B之间加一层:
A<—–>[a——–b]——>B(B1,B2)
a的接口速度接近A,b的接口速度至少为B。那么
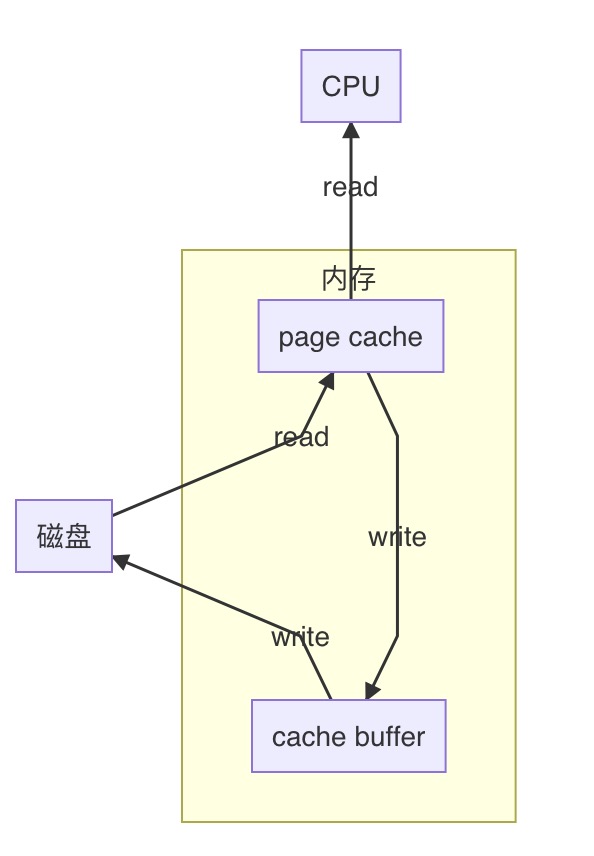
在处理完B1后再处理B2,A就可以直接从a拿数据了,若后面还有B3,B4,Bn需要处理,这将会大大节省时间,这个主要是读的操作就是是缓存,即cache的理解;
以上过程中我们不能忽略了A处理完B1往B写的过程。A处理完可以直接写入[a–b],速度提升了,但不会立刻写到B,在处理完B2,B3 …Bn之后一起写入B,避免了对B频繁操作。这个主要是写的操作就是缓冲,即buffer的理解;
一张图描述如下:
网上有两个有意思的例子:
假设某地发生了自然灾害(比如地震),居民缺衣少食,于是派救火车去给若干个居民点送水。
救火车到达第一个居民点,开闸放水,老百姓就拿着盆盆罐罐来接水。
假如说救火车在一个居民点停留100分钟放完了水,然后重新储水花半个小时,再开往下一个居民点。这样一个白天来来来回回的,也就是4-5个居民点。
但我们想想,救火车是何等存在,如果把水龙头完全打开,其强大的水压能轻易冲上10层楼以上, 10分钟就可以把水全部放完。但因为居民是拿盆罐接水,100%打开水龙头那就是给人洗澡了,所以只能打开一小部分(比如10%的流量)。但这样就降低了放水的效率(只有原来的10%了),10分钟变100分钟。
那么,我们是否能改进这个放水的过程,让救火车以最高效率放完水、尽快赶往下一个居民点呢?
方法就是:在居民点建蓄水池。
救火车把水放到蓄水池里,因为是以100%的效率放水,10分钟结束然后走人。居民再从蓄水池里一点一点的接水。
我们分析一下这个例子,就可以知道Cache的含义了。
救火车要给居民送水,居民要从救火车接水,就是说居民和救火车之间有交互,有联系。
但救火车是“高速设备”,居民是“低速设备”,低速的居民跟不上高速的救火车,所以救火车被迫降低了放水速度以适应居民。
为了避免这种情况,在救火车和居民之间多了一层“蓄水池(也就是Cache)”,它一方面以100%的高效和救火车打交道,另一方面以10%的低效和居民打交道,这就解放了救火车,让其以最高的效率运行,而不被低速的居民拖后腿,于是救火车只需要在一个居民点停留10分钟就可以了。从以上例子可以看出,所谓Cache,就是“为了弥补高速设备和低速设备之间的矛盾”而设立的一个中间层。因为在现实里经常出现高速设备要和低速设备打交道,结果被低速设备拖后腿的情况。
比如说吐鲁番的葡萄熟了,要用大卡车装葡萄运出去卖
果园的姑娘采摘葡萄,当然不是前手把葡萄摘下来,后手就放到卡车上,而是需要一个中间过程“箩筐”:摘葡萄→放到箩筐里→把箩筐里的葡萄倒入卡车。
也就是说,虽然最终目的是“把葡萄倒入卡车”,但中间必须要经过“箩筐”的转手,这里的箩筐就是Buffer。从以上例子可以看出,所谓buffer,就是是“暂时存放物品的空间”。它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用。